用 Azure 打造家庭 AI 聊天機器人:從零到上線的實作記錄
OpenClaw 是一個開源的多通道聊天 agent 閘道;整套服務跑在一台 Ubuntu 24.04 Azure VM 上,前面用 Nginx 反向代理,部署用 Bicep,密鑰收進 Azure Key Vault,日誌進 Log Analytics,模型呼叫交給 Azure AI Foundry。基礎設施月費大約 $40–60 USD,再加上 token 用量;訂閱層級預算警報讓帳單持續在視線內。
這不是一篇產品介紹,而是一份實際把 OpenClaw 架到 Azure 上時留下來的工程筆記。
前言
這套系統的起點其實很單純:我想要一個家裡真的會用到的 AI 聊天機器人,不只是能回答問題,還要能長期穩定地跑著,接 Telegram、LINE,後端模型走 Azure AI Foundry,出了問題也要知道去哪裡查。
真正開始動手之後,問題就不再只是「把服務跑起來」而已,而是:怎麼部署才可重複、怎麼把密鑰收好、怎麼不要一不小心把 Dashboard 直接暴露到公網上、怎麼控制 GPT 成本不要一路往上飆。
所以這篇文章會聚焦在幾件最實際的事:
- 為什麼我最後選了現在這套 Azure 架構
- 怎麼用 Bicep 把整套基礎設施寫成可以重複部署的程式碼
- 安全性有哪些地方是一定要先想清楚的
- 怎麼把 OpenClaw 接到 Azure AI Foundry 的 GPT 模型上
- 上線後怎麼看成本、怎麼避免花費失控
想先掌握整個系列的脈絡,可以從 OpenClaw on Azure 系列總覽 開始。如果你想在這套基礎上繼續擴充,可以再讀 讓 OpenClaw 聽懂語音:整合 MAI-Transcribe-1 語音轉文字完整教學,了解 Azure Speech 與語音訊息轉錄流程;如果你想處理圖片生成與投遞,則可以接著看 讓 OpenClaw 學會畫圖:整合 MAI-Image-2 與 Telegram、LINE、WhatsApp。
一、整體架構
先講結論:我最後沒有把所有東西拆成很多雲端服務,而是選擇用一台 Azure Linux VM 承載 OpenClaw,前面放 Nginx 做反向代理,旁邊再接 Key Vault、Log Analytics 和 Azure AI Foundry。對家庭規模的使用來說,這個架構夠簡單,維運成本也低很多。
使用者(Telegram / LINE / WhatsApp)
│
▼ HTTPS :443
[Azure 公開 IP + NSG]
│
▼
[Nginx 反向代理 :443] ← TLS 終端、Let's Encrypt 憑證
│
▼
[OpenClaw Gateway :18789] ← 只綁定 loopback,外部完全無法存取
│
┌────┴──────────────────┐
│ │
▼ ▼
[Azure Key Vault] [Azure AI Foundry]
所有密鑰集中管理 GPT-5.2-chat 模型
│
▼
[Log Analytics]
日誌 30 天保留
這樣設計的好處是邊界很清楚。對外只有 443、80、22 幾個必要端口;真正的 OpenClaw Gateway 只留在 VM 內部 loopback;模型能力交給 Azure AI Foundry;機密資料則統一放進 Key Vault。換句話說,流量、密鑰、模型和主機責任是分開的,出問題時也比較容易定位。
關鍵設計原則
| 原則 | 做法 |
|---|---|
| Gateway 不對外暴露 | 綁定 127.0.0.1:18789,NSG 明確 Deny |
| 所有密鑰不落地 | 存在 Azure Key Vault,程式動態取用 |
| 基礎設施即程式碼 | 所有 Azure 資源 100% 用 Bicep 定義 |
| 最小化開放端口 | 只開 443(HTTPS)、80(ACME)、22(SSH) |
二、Bicep IaC 實作
如果只是手動在 Portal 裡點一遍,當下當然也能把環境建起來,但第二次、第三次,或幾個月後要重建時,成本就會高很多。這也是我一開始就決定用 Bicep 的原因:把整套 Azure 資源寫成程式碼,之後每次部署都走同一條路。
我把不同責任切成獨立模組,最後由 main.bicep 統一組裝。
2.1 模組地圖
infra/bicep/
├── main.bicep ← 入口點,呼叫所有模組
└── modules/
├── vnet.bicep ← VNet + Subnet
├── nsg.bicep ← NSG 安全規則
├── vm-linux.bicep ← Ubuntu 24.04 VM + 公開 IP + NIC
├── keyvault.bicep ← Key Vault(RBAC 授權)
├── loganalytics.bicep ← Log Analytics(30 天保留)
├── openai.bicep ← Azure AI Foundry + GPT 模型部署
└── budget.subscription.bicep ← 訂閱層級費用預算警報
2.2 VNet 模組(vnet.bicep)
網路層沒有做得太複雜,就是一個 VNet 搭一個專門給 VM 用的子網。對這個案例來說,重點不是炫技,而是先把私有網段劃清楚,讓後續 NSG 和 NIC 掛載都有固定位置可依附。
resource vnet 'Microsoft.Network/virtualNetworks@2023-11-01' = {
name: '${prefix}-vnet'
location: location
properties: {
addressSpace: {
addressPrefixes: ['10.20.0.0/16']
}
subnets: [
{
name: '${prefix}-subnet-vm'
properties: {
addressPrefix: '10.20.1.0/24'
}
}
]
}
}
2.3 NSG 模組(nsg.bicep)
NSG 是整套設計裡很關鍵的一層,因為它決定了外面到底看得到什麼。這裡的原則很簡單:只開真的需要的,其他一律關掉。443 給 webhook,80 給憑證更新,22 留給管理;3389 和 18789 這種不該被外部碰到的,就直接拒絕。
// 允許 HTTPS(Telegram / LINE webhook)
{ name: 'allow-https-443', priority: 100, destinationPortRange: '443', access: 'Allow' }
// 允許 HTTP(Let's Encrypt ACME 驗證)
{ name: 'allow-http-80', priority: 110, destinationPortRange: '80', access: 'Allow' }
// 允許 SSH(強烈建議縮限來源 IP,不要用 * 開放全網際網路)
// 正式環境:把 sourceAddressPrefix 改成你的固定 IP,例如 '203.0.113.10/32'
{ name: 'allow-ssh-22', priority: 120, destinationPortRange: '22', access: 'Allow', sourceAddressPrefix: '<your-admin-ip>/32' }
// 明確拒絕 RDP
{ name: 'deny-rdp-3389', priority: 200, destinationPortRange: '3389', access: 'Deny' }
// 明確拒絕 Gateway Dashboard 從外部存取
{ name: 'deny-gateway-18789', priority: 210, destinationPortRange: '18789', access: 'Deny' }
2.4 VM 模組(vm-linux.bicep)
運算層我最後選擇 Azure Ubuntu 24.04 VM。原因也很務實:OpenClaw 跑在原生 Linux 上最直接,除錯、SSH、systemd、Nginx 這些都很熟,出了問題比較容易查。機器規格則依使用量在 Standard_B2s 和 Standard_D2s_v5 間選擇,前者省錢,後者比較有餘裕。
resource vm 'Microsoft.Compute/virtualMachines@2023-09-01' = {
name: '${prefix}-vm'
location: location
properties: {
hardwareProfile: { vmSize: vmSize }
osProfile: {
computerName: '${prefix}-vm'
adminUsername: adminUsername
// 只用 SSH 金鑰,完全禁用密碼登入
linuxConfiguration: {
disablePasswordAuthentication: true
ssh: {
publicKeys: [
{
path: '/home/${adminUsername}/.ssh/authorized_keys'
keyData: sshPublicKey
}
]
}
}
}
storageProfile: {
imageReference: {
publisher: 'Canonical'
offer: '0001-com-ubuntu-server-noble'
sku: '24_04-lts-gen2'
version: 'latest'
}
}
}
}
2.5 Key Vault 模組(keyvault.bicep)
Key Vault 的角色很單純,但非常重要:所有真正敏感的東西都不應該散落在 VM、repo 或 .env 裡。這裡我選 RBAC 模式而不是舊式 Access Policy,因為權限模型比較一致,也比較符合現在 Azure 的做法。
resource kv 'Microsoft.KeyVault/vaults@2023-07-01' = {
name: '${prefix}kv${uniqueString(resourceGroup().id)}'
location: location
properties: {
sku: { family: 'A', name: 'standard' }
tenantId: subscription().tenantId
enableRbacAuthorization: true // 用 RBAC,不用 Access Policy
enableSoftDelete: true
softDeleteRetentionInDays: 7
publicNetworkAccess: 'Enabled'
}
}
2.6 部署指令
當模組都準備好之後,實際部署反而很單純。從 devcontainer 執行下面這條指令,就能把整套環境建起來:
source .env.local
export VM_SSH_PUBLIC_KEY="$(cat ~/.ssh/id_ed25519.pub)"
az deployment group create \
--resource-group "$AZURE_RESOURCE_GROUP" \
--template-file infra/bicep/main.bicep \
--parameters infra/bicep/params/prod.bicepparam \
--parameters sshPublicKey="$VM_SSH_PUBLIC_KEY"
它背後會依序建立 VNet、NSG、VM、Key Vault、Log Analytics、AI Foundry 和 Budget。也因為全部都是宣告式資源,之後要調整 VM 規格、模型 deployment 或預算門檻,都是回到 Bicep 改完再重跑,而不是進 Portal 手動修。
三、安全性設計
這一段是我最不想妥協的地方。很多 AI side project 一開始都先求「能跑」,安全性等之後再說;但如果一開始就把 Dashboard、SSH、API Key 這些邊界放鬆,後面只會越補越痛苦。
3.1 Gateway 完全不對外暴露
最重要的一條規則是:OpenClaw Gateway 不直接對外。外部請求只能打到 Nginx,Nginx 再轉發到 VM 內部的 loopback 服務。這樣做的好處很直接,外網永遠碰不到真正的 Dashboard port。
[外部網路] ─── NSG Deny :18789 ──→ ✗ 阻擋
[Nginx] ─── proxy :18789 ──→ ✔ 只有 localhost 能到 Gateway
[管理員] ─── SSH Tunnel ──→ ✔ 本機 port-forward 存取 Dashboard
管理員要存取 Dashboard,必須先建立 SSH Tunnel:
ssh -N -L 18789:127.0.0.1:18789 <username>@<your-vm-domain>
# 然後在瀏覽器開 http://127.0.0.1:18789/
3.2 NSG 規則層次
優先權 100 — 允許 :443 (Telegram/LINE webhook)
優先權 110 — 允許 :80 (Let's Encrypt 憑證更新)
優先權 120 — 允許 :22 (SSH,**必須縮限來源 IP**,勿用 * 開放全網)
優先權 200 — 拒絕 :3389 (RDP,徹底關閉)
優先權 210 — 拒絕 :18789 (Gateway Dashboard,loopback only)
優先權 65500 — 拒絕所有其他 (Azure 預設)
⚠️ 安全提醒: SSH(port 22)若來源設為
*,VM 會持續被全球掃描機器人嘗試連線。雖然金鑰認證讓暴力破解無效,但仍會暴露在未來 SSH 漏洞(CVE)的攻擊面下。有固定 IP 的場合,務必把來源縮限到<your-ip>/32。
3.3 所有密鑰存在 Azure Key Vault
密鑰管理也是同樣的思路:不要讓祕密散落。Telegram token、LINE secret、Azure AI Foundry API Key,這些資料如果一份在 repo、一份在 shell history、一份在 VM 上,總有一天會出事。集中進 Key Vault 雖然前期多做一點工,但後面會輕鬆很多。
# 部署後,用腳本把 AI Foundry API Key 存入 Key Vault
uv run oc store-key
# 等同於:
az keyvault secret set \
--vault-name "$KV_NAME" \
--name "azure-openai-api-key" \
--value "$OPENAI_KEY"
3.4 OpenClaw 應用層硬化
除了 Azure 層的網路規則,我也把 OpenClaw 本身收緊。這些設定看起來像小事,但其實都是實際避免誤用或濫用的關鍵。
{
"gateway": {
"bind": "loopback" // Dashboard 只綁 127.0.0.1
},
"channels": {
"telegram": {
"configWrites": false, // 禁止透過聊天更改設定
"dmPolicy": "pairing", // 新用戶必須先審核
"groupPolicy": "allowlist", // 只有白名單群組能使用
"groupAllowFrom": ["<家庭群組ID-1>", "<家庭群組ID-2>"]
}
}
}
| 設定 | 作用 |
|---|---|
configWrites: false |
防止有人透過聊天室改掉 bot 的設定 |
dmPolicy: pairing |
陌生人第一則訊息會被靜默丟棄,需管理員審核 |
groupPolicy: allowlist |
只有列出的家庭群組能收到回覆 |
3.5 SSH 金鑰認證,完全禁用密碼
最後是 SSH。這邊沒有什麼花樣,就是徹底禁用密碼登入,只接受 SSH 金鑰。這不是高級防禦,而是基礎 hygiene;但少了這一步,前面很多保護都會變得沒有意義。
四、成本控制
把服務跑起來不難,讓它每個月帳單還能接受,才是真正的長期題目。這套系統本來就不是高流量產品,所以成本控制的策略不是極致壓榨,而是把幾個最主要的開銷點看住:VM、儲存、日誌,以及 GPT token。
4.1 各資源月費估算(UAE North)
| 資源 | 規格 | 月費估算 |
|---|---|---|
| Linux VM | Standard_B2s(2 vCPU, 4 GB RAM) | ~$30–40 |
| OS Disk | Premium SSD P4 (32 GB) | ~$5 |
| 公開 IP | Standard SKU,靜態 | ~$3 |
| Key Vault | Standard,操作量不多 | 幾乎忽略 |
| Log Analytics | 30 天保留,家庭用量 | < $1/GB |
| Azure AI Foundry | gpt-5.2-chat,按 token 計費 | 視用量而定 |
| 合計基礎設施 | ~$38–48/月 |
LLM 費用視使用量,家庭輕量使用通常每月幾美元到十幾美元。
4.2 三大省錢策略
① 訂閱層級預算警報(Bicep 自動部署)
// budget.subscription.bicep
resource budget 'Microsoft.Consumption/budgets@2023-11-01' = {
name: '${prefix}-monthly-budget'
properties: {
amount: 150 // 設定上限 $150/月
timeGrain: 'Monthly'
notifications: {
// 80% 時發 Email 警告
eighty_percent: {
threshold: 80
contactEmails: [notificationEmail]
}
// 100% 時立即通知
one_hundred_percent: {
threshold: 100
contactEmails: [notificationEmail]
}
}
}
}
② VM 定時自動啟動(Automation Account Runbook)
透過 Automation Account + PowerShell Runbook,每天 08:00 UTC 自動啟動 VM,減少非必要的運行時間:
# runbook-vm-restart.ps1 片段
Connect-AzAccount -Identity
Start-AzVM -ResourceGroupName $ResourceGroup -Name $VMName
③ GPT Token 用量監控
有兩種方式可以追蹤 token 用量:
方法一:透過 OpenClaw CLI(即時查看)
# 在 VM 上查看 LLM 用量
ssh <username>@<your-vm-domain> 'openclaw status --usage'
方法二:Azure AI Foundry Portal(圖表 + 歷史趨勢)
在 Azure AI Foundry Portal 裡,進入你的 Hub → Metrics 頁面,可以看到:
| 指標 | 意義 |
|---|---|
TokenTransaction |
每次請求消耗的 token 數 |
ProcessedPromptTokens |
Input tokens(含 system prompt + tools) |
GeneratedCompletionTokens |
Output tokens |
TotalTokens |
兩者合計,對應帳單金額 |
也可以在 Azure Portal → Cost Analysis 裡按資源篩選 Cognitive Services,看實際產生的費用,設定時間範圍觀察用量趨勢。
以下是最近一週(Mar 8–14)的實際費用截圖,整週累計 £17.64,遠低於 £150/月的預算上限:
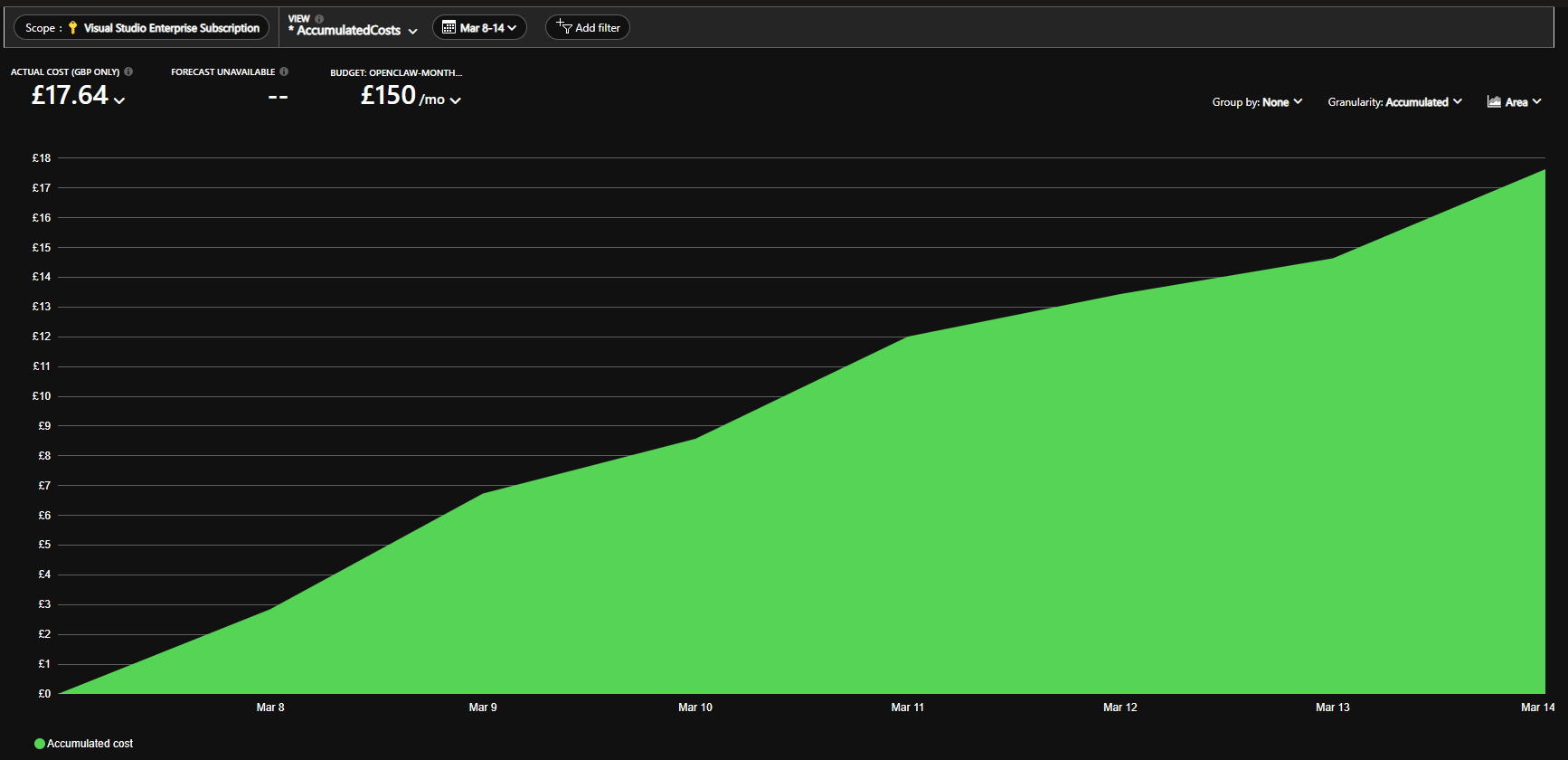
這種圖表很好用,因為它不是抽象的「應該很省」,而是真的能看到成本曲線怎麼走。圖中可以看到費用在後段增長放緩,這和 VM 的排程啟停、整體使用量維持在家庭場景有直接關係。
如果要更細地看模型實際吃掉多少 token,Azure AI Foundry 的 Resource usage 頁面也很有幫助。下面這張圖是最近 7 天 gpt-5dot2-chat deployment 的使用情況:
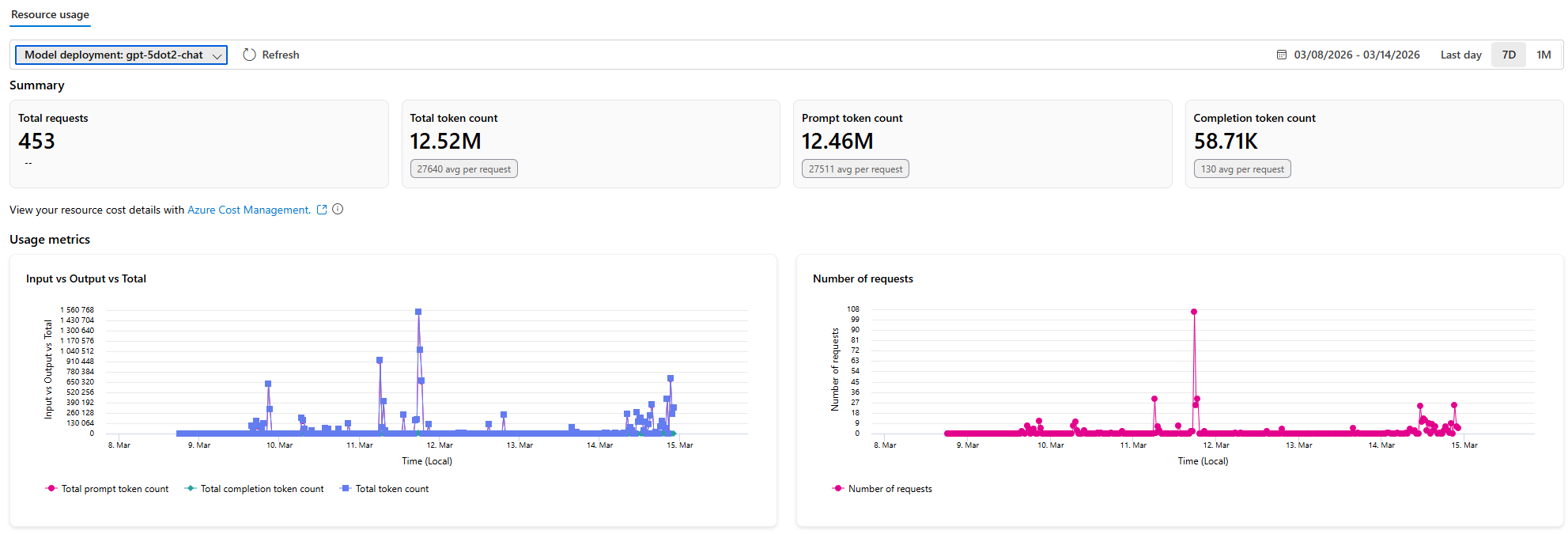
從這張圖可以直接讀到幾個重點:7 天內總共處理了 453 次 requests,總 token 數約 12.52M,其中 12.46M 幾乎都來自 prompt tokens,completion tokens 只有 58.71K。這代表目前這套 OpenClaw 工作負載的成本主要不是出在模型回覆太長,而是 system prompt、tool schema、上下文和多工具呼叫本身就相對重。
另一個值得注意的數字是平均每次 request 約 27,640 tokens,而平均 completion 只有 130 tokens。這很符合 agent 型工作流的特徵:前置上下文很厚,真正模型吐出的最終文字反而不長。對成本優化來說,後續如果要再省,通常優先檢查的會是 prompt 結構、tool 數量和上下文裁剪,而不是先去縮短最終回答。
每個帶 21 個 tool 的請求約消耗 11–13K input tokens。Token 計費在量少時很便宜(家庭用途通常每月 $3–15 USD)。
如果想把每一次模型呼叫對應回觸發它的 agent 步驟,可以參考 為 AI Foundry 呼叫加上 OpenTelemetry 追蹤。
五、串接 Azure AI Foundry GPT 模型
模型整合若不穩,整個系統就只是個轉發器。這一段就是怎麼把 OpenClaw 接上 Azure AI Foundry 的 GPT 模型。
5.1 用 Bicep 部署 AI Foundry 資源
這裡我沒有走舊式 kind: OpenAI 資源,而是直接用 kind: AIServices。這樣比較符合現在 Azure AI Foundry 的路徑,也比較容易和 Hub / Project 那套管理方式接起來。Azure AI Foundry 是現在 Azure 上統一管理 OpenAI 等模型部署的平台;舊的 Azure OpenAI Service(kind: OpenAI)正在被收攏進 Foundry,新環境應該直接走 Foundry 路徑。
openai.bicep 主要建立三類資源:
// 1. AIServices 帳號(不是舊的 kind: OpenAI)
resource openai 'Microsoft.CognitiveServices/accounts@2024-10-01' = {
name: '${prefix}-foundry-${unique}'
location: location
kind: 'AIServices' // 關鍵!要用 AIServices,不是 OpenAI
sku: { name: 'S0' }
properties: {
customSubDomainName: '${prefix}-foundry-${unique}'
publicNetworkAccess: 'Enabled'
disableLocalAuth: false // 允許 API Key 認證
}
}
// 2. 模型部署(gpt-5.2-chat)
resource deployments 'Microsoft.CognitiveServices/accounts/deployments@2024-10-01' = [
for deployment in modelDeployments: {
parent: openai
name: deployment.name // 例如 'gpt-5dot2-chat'
sku: {
name: 'GlobalStandard' // GlobalStandard = 全球 routing,較便宜
capacity: 10 // 100K TPM 容量
}
properties: {
model: {
format: 'OpenAI'
name: 'gpt-5.2-chat'
version: '2026-02-01'
}
}
}
]
// 3. AI Foundry Hub(讓 Azure Portal 有追蹤 UI)
resource hub 'Microsoft.MachineLearningServices/workspaces@2024-10-01' = {
name: '${prefix}-hub-${unique}'
kind: 'Hub'
identity: { type: 'SystemAssigned' }
properties: {
storageAccount: storage.id
publicNetworkAccess: 'Enabled'
}
}
5.2 部署流程
模型部署上,我沒有只放一個主模型,而是同時準備了 primary 和 failover。主力是 gpt-5.2-chat,備援是 gpt-5.3-chat。這個設計不是為了炫耀多模型,而是很實際地降低單一 deployment 抽風時整個服務停掉的機率。
// prod.bicepparam — 同時部署 primary 與 failover 模型
param openaiLocation = 'swedencentral'
param openaiModelDeployments = [
{
name: 'gpt-5dot2-chat'
modelName: 'gpt-5.2-chat'
modelVersion: '2026-02-10'
skuName: 'GlobalStandard'
skuCapacity: 100 // Primary:100K TPM
}
{
name: 'gpt-5.3-chat'
modelName: 'gpt-5.3-chat'
modelVersion: '2026-03-03'
skuName: 'GlobalStandard'
skuCapacity: 150 // Failover:150K TPM,容量更大
}
]
部署完成後,Azure AI Foundry 端會同時看到兩個 deployment,都已經可以被同一組 provider 設定引用:
az deployment group create \
--resource-group "$AZURE_RESOURCE_GROUP" \
--template-file infra/bicep/main.bicep \
--parameters infra/bicep/params/prod.bicepparam
5.3 把 API Key 存入 Key Vault
資源建立好之後,下一步不是立刻去改 OpenClaw 設定,而是先把 API Key 正規地收進 Key Vault。這樣後續不管是輪替、查詢,還是重新配置 VM,都比較有秩序。
# 用腳本自動取得 API Key 並存進 Key Vault
uv run oc store-key
# 等同於以下 az CLI 操作:
OPENAI_KEY=$(az cognitiveservices account keys list \
-g "$AZURE_RESOURCE_GROUP" -n "$OPENAI_ACCOUNT_NAME" \
--query key1 -o tsv)
az keyvault secret set \
--vault-name "$KV_NAME" \
--name "azure-openai-api-key" \
--value "$OPENAI_KEY"
5.4 在 OpenClaw 設定 Provider
真正容易踩坑的地方在這裡。Azure AI Foundry 雖然提供的是 OpenAI 相容介面,但認證細節和一般 OpenAI API 並不完全一樣。如果照很多網路範例直接用 Bearer token,最後多半會卡住。
{
"models": {
"providers": {
"azure-openai-responses": {
"api": "openai-responses",
"baseURL": "https://<資源名稱>.openai.azure.com/openai/v1",
"apiKey": "<API_KEY>",
"authHeader": false, // 關鍵!停用預設 Bearer token
"headers": {
"api-key": "<API_KEY>" // Azure 用自己的 header
},
"compat": {
"supportsStore": false // Azure 不支援 store 參數
}
}
}
},
"agents": {
"defaults": {
"models": {
"primary": "azure-openai-responses/gpt-5.2-chat",
"failover": [
"azure-openai-responses/gpt-5.3-chat" // 自動 failover 到 gpt-5.3-chat
],
"streaming": false // Azure Responses API 有 bug,關掉 streaming
}
}
}
}
Failover 的運作邏輯也很直白:當 gpt-5.2-chat 回傳錯誤,例如 429 超過 TPM 限制,或 5xx 代表服務短暫異常時,OpenClaw 就改試 gpt-5.3-chat。對使用者來說,這件事通常是無感的;對維運者來說,則多了一層緩衝。兩個模型同屬同一個 AI Foundry 帳號,共用同一個 endpoint 和 API Key,不需要額外維護第二套認證。
重要:
authHeader: false+headers.api-key這個組合是必要的。 Azure AI Foundry 不接受Authorization: Bearer <key>這種格式, 必須改用api-key: <key>header。API Key 要同時出現在apiKey欄位和headers.api-key。
5.5 用腳本自動設定 VM
這一步我也盡量避免手工操作。直接 SSH 進 VM 改 JSON 當然可以,但這種流程最容易在下次重建時忘記。比較穩的做法,是把它收斂成固定腳本:
uv run oc configure-openai \
"$VM_IP" \
"$OPENAI_ENDPOINT" \
"$OPENAI_KEY" \
"gpt-5.2-chat"
腳本會:
1. 備份目前的 openclaw.json
2. 透過 SSH 將 provider 設定 merge 進去
3. 重啟 Gateway 讓設定生效
5.6 已知問題:Streaming 必須關掉
這次整合過程裡,最煩的一個坑是 Azure OpenAI Responses API 的 streaming 問題。當 stream: true,而請求裡又帶有 function_call_output items 時,API 會報錯;改成 stream: false 就正常。
設定方式:
{
"agents": {
"defaults": {
"models": {
"streaming": false
}
}
}
}
所以我最後的選擇很保守:先關掉 streaming,優先換取穩定性。代價只是使用者不會看到逐字輸出的效果,但整體功能和正確性不受影響。
六、完整架構圖
一句話總結:外部流量先進 Nginx,內部服務留在 loopback,祕密資料交給 Key Vault,模型能力交給 Azure AI Foundry。
graph TB
Telegram[Telegram]
LINE[LINE]
WhatsApp[WhatsApp]
Admin[Admin Devcontainer]
subgraph SUB[Azure Subscription]
Budget[Budget 150 per month]
subgraph RG[Resource Group UAE North]
NSG[NSG Allow 443 80 22 Deny 3389 18789]
PIP[Public IP Static]
subgraph VM[Ubuntu VM Standard B2s]
Nginx[Nginx 443 TLS]
Gateway[OpenClaw Gateway 18789 loopback only]
end
KV[Key Vault RBAC]
LA[Log Analytics 30 days]
end
subgraph FOUNDRY[Azure AI Foundry Sweden Central]
GPT[gpt 5.2 chat GlobalStandard 10K TPM]
end
end
Telegram -->|HTTPS 443| PIP
LINE -->|HTTPS 443| PIP
PIP --> NSG --> VM
Nginx --> Gateway
WhatsApp -.->|Baileys Protocol| Gateway
Gateway -->|Secrets| KV
Gateway -->|Logs| LA
Gateway -->|API Key| GPT
Admin -->|Bicep deploy| RG
Admin -.->|SSH Tunnel 22| VM七、部署驗證
部署完成後,我不會只看 Azure Portal 顯示成功就收工,還會跑一次 smoke test,確認 Gateway、channel 和 reminder plugin 都真的活著。
uv run oc smoke-test <your-vm-domain>
預期輸出:
=== 1/3 Gateway /health ===
{"ok":true,"status":"live"}
gateway: OK
=== 2/3 Channel probes ===
channels OK: telegram, line
=== 3/3 Reminder plugin ===
reminder plugin: loaded
smoke-test: PASS
那一行 reminder plugin: loaded 背後的實作細節,可以參考 Reminder plugin 的設計細節。
總結
| 面向 | 做法 |
|---|---|
| 基礎設施 | 100% Bicep IaC,一條指令部署所有資源 |
| 安全性 | Gateway loopback-only、Key Vault 存密鑰、NSG 最小開放、SSH key-only |
| 成本 | Budget 警報 + VM 定時排程 + Token 用量監控 |
| AI 模型 | Azure AI Foundry (AIServices) + azure-openai-responses provider,注意 authHeader: false 和關掉 streaming |
回頭看,這套架構其實沒有什麼特別花俏的地方。它比較像是一套刻意收斂過的選擇:不用過度複雜的雲端拓撲、不把安全性留到最後、不把模型設定藏在手工操作裡。Bicep 負責讓部署可重複,Key Vault 和 NSG 把邊界守住,Azure AI Foundry 提供模型能力,Budget 和監控把成本壓在看得見的範圍內。
如果使用場景和我差不多,想做的是一套家庭規模、可長期運行、能自己掌握部署與成本的 AI 機器人,那這套做法是很務實的一條路。家庭用途下,整體基礎設施大致落在每月 $40–60 USD,再加上依使用量變動的 GPT 費用,通常是可以接受的範圍。