把 OpenClaw 對話搬進 Azure AI Foundry Tracing:從家庭聊天到可回放的 AI Debugging
把 OpenClaw(一個開源的多通道 chat agent gateway)接上 Telegram、LINE、WhatsApp 之後,我遇到的麻煩不是服務有沒有啟動,而是很難回答一句話:它剛才到底看到了什麼,才會這樣回?這篇是 OpenClaw on Azure 系列 的其中一篇,記錄我把 OpenClaw Gateway 的對話、模型呼叫、tool call、token 用量和多模態內容接到 Azure AI Foundry Tracing 的過程。目標很簡單:出問題時,不用猜。
我喜歡 Azure AI Foundry Tracing 的地方,是它不用逼你在一堆 log、tool output、模型回覆和 token 數字之間來回跳。這些線索會被放在同一個畫面裡。做 agent 時,這比一張漂亮 dashboard 實用得多,因為你可以直接追:是哪一步開始走歪?
後來我也發現,Tracing 很適合拿來接 evaluation。固定測試對話跑完後,我不只想知道 agent 有沒有回覆;我還想知道模型看到了什麼、用了哪些工具、最後產生了什麼內容。這些 trace 讓穩定性變成可以重跑和比較的東西,而不是憑感覺說「這版好像比較穩」。
這篇會說明 OpenClaw 如何把模型呼叫、工具呼叫、token 用量,以及被 redacted 的多模態內容送進 Azure AI Foundry Tracing。也會說明這些 traces 如何成為可重跑 agent evaluation 的證據。
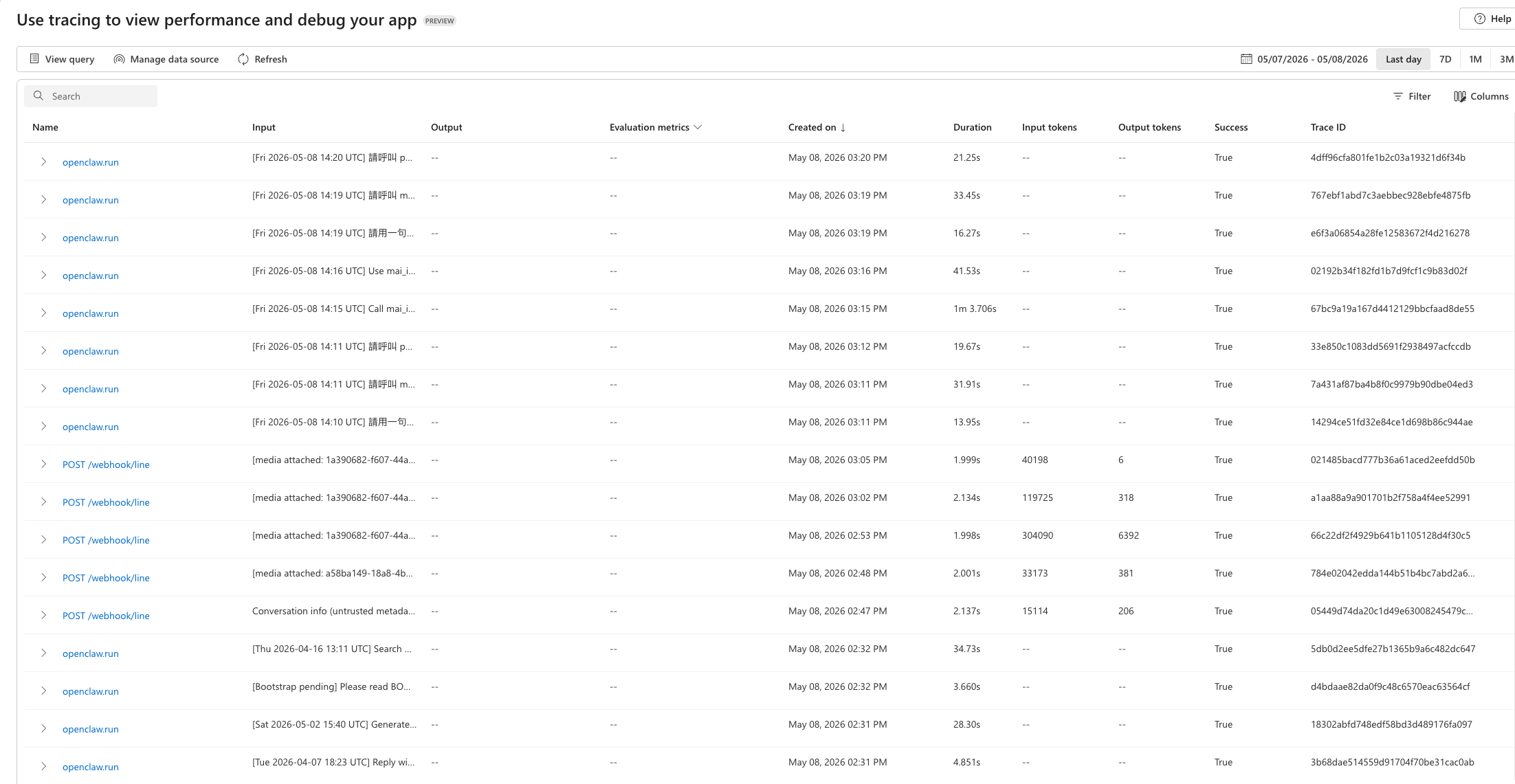
Azure AI Foundry Tracing tab 會把每一次 OpenClaw 執行列成一筆 trace。從 LINE webhook 進來的真實對話會顯示 token 用量;用 CLI 直接跑的 eval trace 則可能沒有顯示,因為它不是從 HTTP webhook 進來的請求。
先看成果
接好之後,一則真實訊息不再只是一行 log。它會變成一段可以展開的 trace:
POST /webhook/line 或 POST /webhook/telegram
└─ openclaw.message_processed
└─ openclaw.run
├─ openclaw.context.assembled
├─ openclaw.model.call
├─ openclaw.tool.execution
└─ chat.completions gpt-5dot4
我最常看的幾件事是:
- 使用者實際輸入了什麼。
- 模型最後回了什麼。
- 它中間呼叫了哪些工具,例如圖片生成、PDF 產生、搜尋或語音轉文字。
- 每次 model call 用了多少 input / output tokens。
- 同一個 Telegram / LINE / WhatsApp 對話是否被歸在同一條 conversation timeline。
- 圖片這類多模態內容是否被安全地 redacted,而不是把 base64 原始資料整包寫進 telemetry。
我不想只靠幾張截圖說「看起來有通」。所以另外做了一個可重跑的驗證流程:在 live VM 上跑三段固定對話,再到 Application Insights 查回對應的 model-call traces。2026-05-08 的實跑結果是 3/3 PASS,純文字、圖片生成、PDF 產生三種情境都能在 Foundry Tracing 裡被回放和檢查。
這裡開始有 evaluation 的味道了:evaluation 定義 agent 應該穩定完成哪些任務,Tracing 則留下每次執行的證據。以後模型、prompt、plugin 或工具鏈升級時,可以拿 trace 裡的 prompt、tool call、completion 和 token 用量來比,而不是等使用者說「它今天怪怪的」。
我先選了三段夠小、但會碰到核心問題的 scenario:
| Scenario | 使用者訊息 | 驗證重點 |
|---|---|---|
text-001 |
請用一句話形容今天台北的天氣。 | 純文字 prompt / completion 可以直接閱讀,並有 gen_ai.provider.name、gen_ai.operation.name、gen_ai.conversation.id。 |
image-gen-001 |
請呼叫 mai_image_generate 畫一張溫馨家庭客廳。 |
圖片生成結果回傳 Blob URL,trace 裡有 openclaw.content.image.0.redacted=true,沒有 data: URL 或 base64。 |
pdf-publish-001 |
請呼叫 publish_file 產出家庭備忘 PDF。 |
PDF tool call 的最終下載連結出現在 gen_ai.completion.0.content,可供回放與稽核。 |
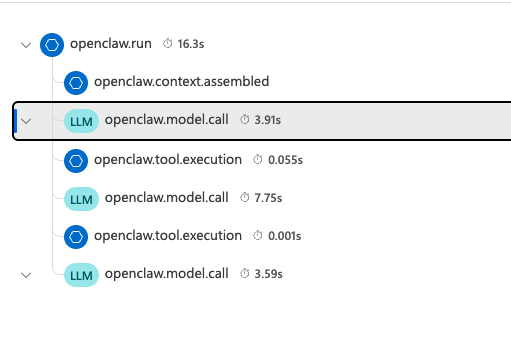
展開單一 openclaw.run 後,可以看到這次 agent turn 裡發生了哪些步驟:先組裝 context,接著呼叫模型,中間穿插 tool execution,最後再回到模型產生回覆。
相關 OpenClaw 文章
這篇接在前面幾篇 OpenClaw 實作之後讀會比較順:
- 基礎部署:用 Azure 打造家庭 AI 聊天機器人:從零到上線的實作記錄。
- 圖片生成:讓 OpenClaw 學會畫圖:整合 MAI-Image-2 與 Telegram、LINE、WhatsApp。
- 語音轉文字:讓 OpenClaw 聽懂語音:整合 MAI-Transcribe-1 語音轉文字完整教學。
- 長期任務和 plugin:為 OpenClaw 打造自然語言提醒與排程任務系統。
為什麼 OpenClaw 需要這個
家庭 AI 助手接到群組和私訊之後,會開始變得很難用傳統 log 除錯。
使用者看到的是:
下載連結:
https://...blob.core.windows.net/documents/.../family-memo.pdf
但營運者真正想知道的是:
- 這次是誰觸發的?Telegram、LINE 還是 WhatsApp?
- 模型看到的完整 prompt 是什麼?有沒有混入上一輪對話?
- 它為什麼決定呼叫
publish_file? - 工具是否成功?慢在哪裡?
- 最後回覆是否真的包含使用者要的 PDF?
- 如果訊息裡有圖片,trace 會不會把圖片 bytes 直接留下來?
傳統 application log 不是不能用,但它太平了。要回答上面這些問題,我得拿時間戳、session id、request id 自己拼,拼完還不一定確定中間哪一步影響了後面的回覆。
Tracing 幫上的忙,是把一次對話的來龍去脈排清楚。系統先準備了哪些資料,模型接著怎麼判斷,中間有沒有呼叫工具,工具回來的結果又怎麼影響下一次回覆,這些都能沿著同一條 trace 看下去。AI 助手的很多問題不是某一步炸掉,而是前面看到的內容和中間做出的選擇慢慢堆出來的。
架構:從 webhook 到 Foundry portal
先畫成一張圖,不然後面很容易混在一起:
flowchart TD
channels["Telegram / LINE / WhatsApp"]
webhook["HTTPS webhook"]
gateway["OpenClaw Gateway<br/>on Azure VM"]
diag["diagnostics-otel plugin"]
foundry["openclaw-foundry-integration plugin"]
monitor["@azure/monitor-opentelemetry preload"]
core["openclaw.* spans"]
enrichment["chat.completions / execute_tool<br/>enrichment spans"]
appi["Application Insights / Log Analytics"]
portal["Azure AI Foundry<br/>Project Tracing tab"]
channels --> webhook --> gateway
gateway --> diag --> core --> monitor
gateway --> foundry --> enrichment --> monitor
monitor --> appi --> portal這裡有兩個 plugin 角色不同:
diagnostics-otel是 OpenClaw 的內建診斷 plugin,負責產生openclaw.run、openclaw.model.call、openclaw.tool.execution這些可信的核心 spans。openclaw-foundry-integration是我另外寫的 Foundry enrichment plugin,負責補上 Foundry portal 需要的 OpenTelemetry GenAI semantic conventions,例如gen_ai.conversation.id、gen_ai.provider.name、gen_ai.operation.name、prompt / completion 內容、tool I/O 和 token usage。
這兩個 plugin 都採用與建在同一個 OpenClaw runtime 上的 reminder plugin相同的 extension model,所以長期任務和診斷介面在不同 plugin 之間能保持一致。
Exporter 則不是用 OTel Collector,而是用 @azure/monitor-opentelemetry preload:
Environment=APPLICATIONINSIGHTS_CONNECTION_STRING=<from-key-vault>
Environment="NODE_OPTIONS=--require /opt/openclaw/appinsights-setup.js"
Environment=OPENCLAW_OTEL_PRELOADED=1
Environment=OTEL_SERVICE_NAME=openclaw-gateway
Environment=OTEL_SEMCONV_STABILITY_OPT_IN=gen_ai_latest_experimental
我一開始卡住的地方,是把「產生 OpenTelemetry spans」和「把資料送進 Application Insights」想成同一件事。OpenClaw plugin 產生的是 OTel spans;但 Application Insights resource 不是一個可以直接把 OTLP endpoint 指過去的 receiver。
flowchart TD
openclaw["OpenClaw Gateway"]
spans["OpenClaw plugins<br/>create OTel spans"]
direct["Direct OTLP endpoint<br/>to Application Insights"]
preload["Chosen path:<br/>Azure Monitor SDK preload"]
collector["Alternative path:<br/>run an OTel Collector"]
exporter["Azure Monitor<br/>OpenTelemetry Exporter"]
connection["Application Insights<br/>connection string"]
appi["Application Insights"]
foundry["Azure AI Foundry<br/>Tracing tab"]
openclaw --> spans
spans -. "not the path used" .-> direct
spans --> preload --> exporter --> connection --> appi --> foundry
spans -. "heavier option" .-> collector --> exporter
classDef blocked fill:#fff1f2,stroke:#be123c,color:#7f1d1d
classDef chosen fill:#ecfdf5,stroke:#047857,color:#064e3b
class direct blocked
class preload,exporter,connection,appi,foundry chosen最後我選 preload,理由其實很普通:Microsoft 的 OpenTelemetry 指南使用 Azure Monitor OpenTelemetry Distro 搭配 Application Insights connection string 送資料;另一份設定文件則把 OTLP Exporter 描述成「額外送到 OTLP receiver,例如 Collector」的選項。既然只是要把 OpenClaw process 裡的 spans 送進 Azure Monitor,多跑一個 collector container 反而多了一層維運。所以我讓 Azure Monitor SDK 在 Node.js process 啟動前先註冊 global OTel SDK,再讓 OpenClaw plugin 把 spans 寫進這個 SDK。
實際生產環境還有一些 Key Vault、systemd drop-in、VM 升級流程與內部 runbook 細節;這篇先聚焦在公開可理解的 tracing 架構與踩坑經驗。
最難的地方:Foundry portal 看的不是你以為的 span
一開始我以為只要寫一個 plugin,在 model call 期間拿到 active span,補上 gen_ai.conversation.id 和 prompt / completion,就可以結束。
結果不是。
第一個問題是 OpenClaw 的 diagnostics-otel 不是用標準的 withSpan(callback) pattern 把 span 設為 active。也就是說,在 sibling plugin 裡呼叫 trace.getActiveSpan(),拿不到我想改的 openclaw.model.call span。
第二個問題更關鍵:Azure AI Foundry portal 的 Input / Output panel 主要讀的是 trusted openclaw.model.call span。可是這個 span 由 diagnostics-otel 擁有,外部 plugin 不能直接寫屬性進去。OpenClaw 把那個 span 放在 internal diagnostics capability 後面,而這個 capability 只授給 bundled plugin。
所以最後變成兩層設計:
openclaw-foundry-integration自己 emitchat.completions <model>spans,這些 spans 帶完整 GenAI metadata,可以用 KQL 和 eval gate 驗證。oc bundle-diagnostics-otel把diagnostics-otel搬進 OpenClaw 的 stock extensions 目錄,讓它取得 internal diagnostics capability,並套上一個 local patch,把 prompt / completion content 和 legacy GenAI content events 寫回 trustedopenclaw.model.callspan。
這個 patch 不是漂亮的第一選擇,但它是目前最小可行的 production workaround。它有三個保護:
- Fail loud:patch anchor 找不到就中止,不會半套上線。
- Idempotent:同版本重跑會回報已套用。
- Version-aware:patch 版本更新時會移除舊 block 再重貼。
長期來看,最好的解法是 OpenClaw upstream 原生支援這些 GenAI content attributes / events,或至少把 diagnostics-otel 正式 bundle 進 dist/extensions/。在那之前,這個 local patch 是讓 Foundry portal 真正能顯示 Input / Output 的橋。
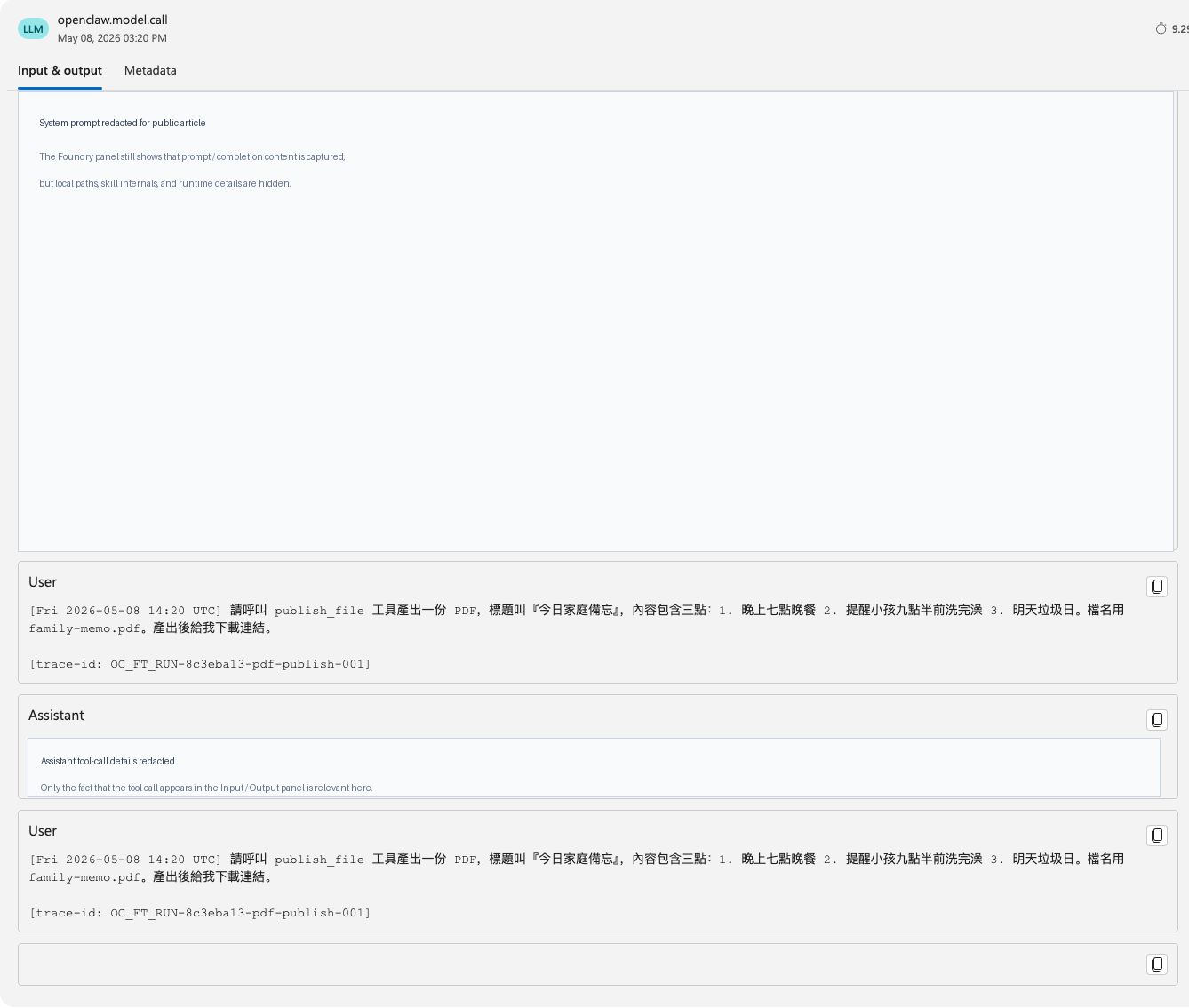
修完 trusted span 內容之後,openclaw.model.call 的 Input & Output panel 不再是空白。這張圖保留 portal 中能看到 user prompt 與 assistant tool call 的重點,並遮掉與公開文章無關的內部路徑和 tool call 細節。
多模態內容:trace 要可讀,但不能留下圖片 bytes
多模態這段我特別保守。圖片進 trace 時,我只留下可讀摘要和 metadata,不留下 raw bytes。
在圖片情境裡,模型或工具可能處理這種內容:
{
"type": "image_url",
"image_url": {
"url": "data:image/png;base64,iVBORw0KGgo..."
}
}
這種東西如果原封不動寫進 trace,會有兩個問題:
- 可讀性很差:Foundry portal 的 Input panel 會被一大坨 base64 淹沒。
- 隱私風險變高:圖片本身可能包含家人、住家、文件或其他敏感資訊。
所以現在的 content normalizer 會把圖片內容轉成 deterministic placeholder,例如:
[image: image/png, id=889444bc-2de3-4f7d-a28b-f08d835bab29, redacted]
在 2026-05-08 的 smoke test 中,圖片生成情境送出一張 1.37 MB(1,370,376 bytes)的 PNG,trace 上只留下被 redacted 的 metadata:
gen_ai.input.images_count = 1
openclaw.content.image_count = 1
openclaw.content.image.0.mime_type = image/png
openclaw.content.image.0.bytes = 1370376
openclaw.content.image.0.redacted = true
這樣看 trace 的時候仍然知道「這次有圖」、「圖多大」、「有沒有被 redacted」,但 telemetry 裡不會留下圖片本體。

圖片進 trace 之後只留下 metadata:gen_ai.input.images_count 和 openclaw.content.image_count 告訴我們這次有圖片,openclaw.content.image.0.redacted: true 則表示原始圖片內容已遮蔽。畫面中沒有 data:image 或 base64 長字串,trace 因此比較可讀,也比較安全。
三段可重跑的對話範例
我不想只靠肉眼看 portal 說「應該可以」。所以這次加了一個新的 evaluator:oc eval foundry-trace。
它做的事很單純:
- 把三段固定 scenario 送到 live VM 上的
openclaw agent --json。 - 每段 prompt 都加上一個不影響語意的 sentinel,例如
OC_FT_RUN-8c3eba13-image-gen-001。 - 等 App Insights ingestion。
- 用 KQL 查
chat.completionsenrichment spans,並要求 prompt content 裡包含該 sentinel。 - 檢查每段 scenario 的 signal 是否符合預期。
- 產生 blog-friendly markdown report 和 machine-readable JSONL。
範例 1:純文字
請用一句話形容今天台北的天氣,並附上一個合適的 emoji。回覆控制在 30 個字以內。
回覆:
台北今天晴時多雲,約21°C 🌤️
這段用來驗證最乾淨的 case:prompt 和 completion 都是純文字,span 上應該能看到:
gen_ai.provider.name = azure.ai.openai
gen_ai.operation.name = chat.completions
gen_ai.request.model = gpt-5dot4
gen_ai.conversation.id = oc-60ade8193223dd14
gen_ai.usage.input_tokens = 831
gen_ai.usage.output_tokens = 621
範例 2:圖片生成
請呼叫 mai_image_generate 工具,畫一張溫馨的家庭客廳:晚餐時間、暖色燈光、桌上有湯。畫好後用一句話描述你做了什麼。
回覆會包含一個公開 Blob URL 和一句描述:
https://...blob.core.windows.net/images/...png
我畫了一張晚餐時分、暖色燈光下的溫馨家庭客廳,桌上擺著熱湯與家常菜。
這段重點不是「它有沒有畫圖」而已,而是 trace 裡必須證明圖片內容被 redacted:
openclaw.content.image.0.mime_type = image/png
openclaw.content.image.0.bytes = 1370376
openclaw.content.image.0.redacted = true
範例 3:PDF 產生
請呼叫 publish_file 工具產出一份 PDF,標題叫『今日家庭備忘』,內容包含三點:1. 晚上七點晚餐 2. 提醒小孩九點半前洗完澡 3. 明天垃圾日。檔名用 family-memo.pdf。產出後給我下載連結。
回覆:
下載連結:
https://...blob.core.windows.net/documents/.../family-memo.pdf
這段用來驗證工具回合最後的 user-visible artifact 有沒有進 trace:
gen_ai.completion.0.content = 下載連結: https://...family-memo.pdf
這三段測試最後都通過;下面的截圖則取自同一套 tracing pipeline 的實際 Foundry portal 畫面。
一個容易誤會的地方:為什麼 token 欄位有時是空的
在 Foundry portal 的 trace list 裡,你會看到有些 row 的 Input tokens / Output tokens 有值,有些是空白。這不是資料不見了,而是 portal 的 roll-up 行為不同。
真實 webhook trace 通常長這樣:
POST /webhook/line
└─ openclaw.message_processed
└─ openclaw.model.usage
Foundry portal 會把子層 openclaw.model.usage 的 token usage roll up 到 HTTP request root,所以 POST /webhook/line 那一列會看到 input / output tokens。
但 oc eval foundry-trace 是直接在 VM 上呼叫 CLI:
openclaw.run
└─ openclaw.model.usage
這種 non-HTTP root,portal 不會自動 roll up token 欄位。因此 openclaw.run 那一列可能是空白。token 資料其實還在:
openclaw.model.usagespan 上有gen_ai.usage.input_tokens/gen_ai.usage.output_tokens。chat.completions <model>enrichment span 上也有同名 attributes。
所以寫 blog 時,截圖建議用真實 Telegram / LINE webhook trace;eval report 則用來做可重跑驗證。
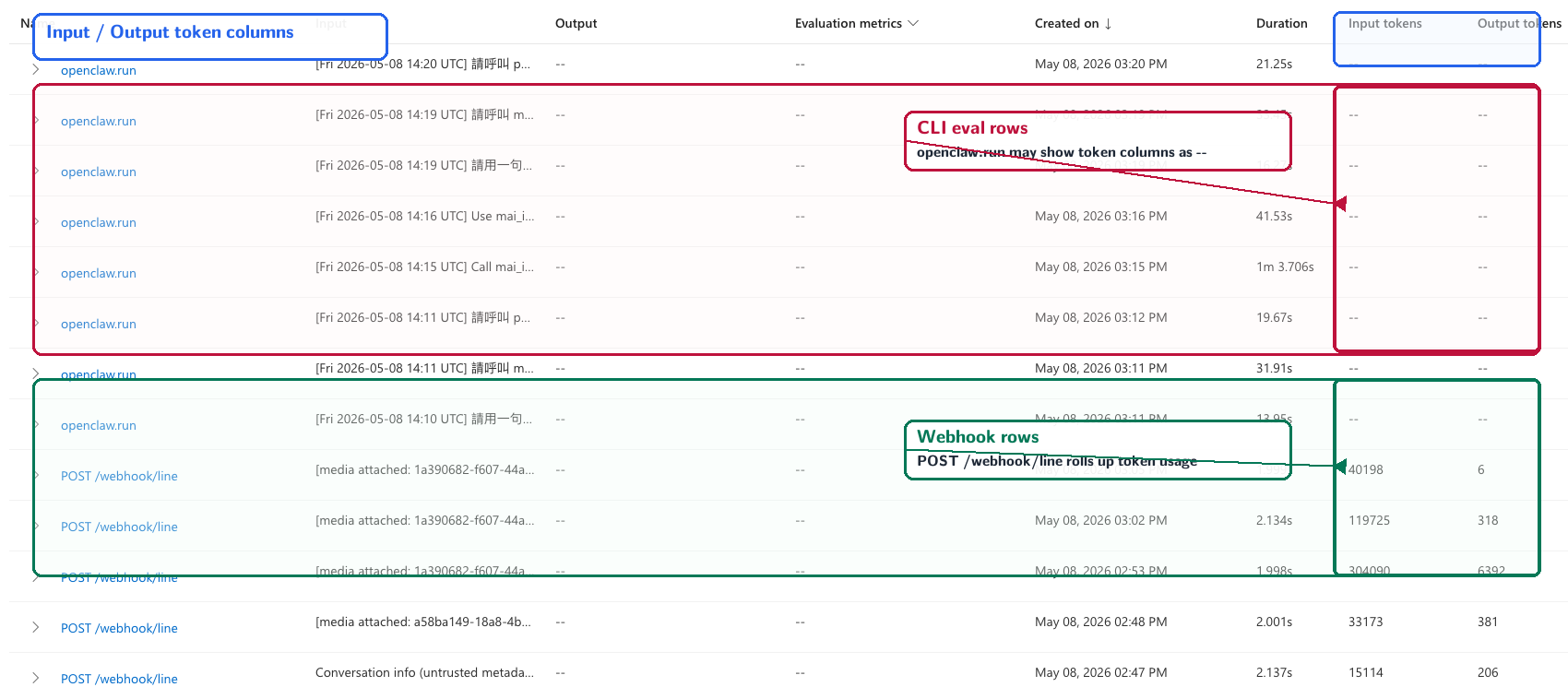
同一個 trace list 裡可以看到兩種行為:openclaw.run 這類 CLI eval rows 的 token 欄位可能顯示 --;從 POST /webhook/line 進來的真實 webhook rows 則會在 Input tokens / Output tokens 欄位看到數字。這就是「token 不是不見了,而是 portal roll-up 的根節點類型不同」。
Rollout 順序
實際上線順序很重要,因為 OpenClaw 對 plugin config 是 fail-closed 的。如果 config 先引用了一個還沒安裝的 plugin,gateway 會拒絕啟動。
我的內部 CLI 流程大致是這個順序;下面用 <gateway-host> 代表實際的 OpenClaw Gateway hostname:
# 1. 安裝 Foundry enrichment plugin
uv run oc install-foundry-plugin <gateway-host>
# 2. 設定 Azure Monitor preload
uv run oc setup-appinsights <gateway-host>
# 3. 部署 openclaw.json,打開 diagnostics.otel 和 plugin allow-list
uv run oc deploy-config <gateway-host>
# 4. 把 diagnostics-otel 搬進 stock extensions,並套上 Foundry content patch
uv run oc bundle-diagnostics-otel <gateway-host>
# 5. 驗證
uv run oc verify-foundry-plugin <gateway-host>
uv run oc smoke-test <gateway-host> --extended
uv run oc eval foundry-trace <gateway-host>
第 4 步是目前最不尋常、也最值得記住的 workaround。每次 oc upgrade 之後,都要重新跑一次 oc bundle-diagnostics-otel,因為 OpenClaw npm upgrade 會重建 bundled plugin 目錄。這件事已經寫進升級流程,避免下次升版後 tracing 突然變空。
隱私、成本與保留期
這套 tracing 會捕捉 prompt、completion 和 tool I/O。這是刻意的選擇,不是預設安全假設。
家庭場景下,我選擇打開內容捕捉,理由是:
- 家人問「為什麼它這樣回」時,沒有 input / output 內容就很難 debug。
- Telemetry 留在自己的 Azure subscription,背後是自己的 Log Analytics workspace。
- Retention 是 30 天,到期自動清掉。
- 圖片 bytes 不寫入 trace,只保留 redacted placeholder 和 metadata。
- 量級很小,家庭使用量遠低於 Application Insights / Log Analytics 常見免費額度。
不過這不是所有場景都該照抄。如果是公司客服、醫療、金融或任何高敏感資料,應該改成更保守的 captureContent policy,或者只在 staging / debug session 打開內容捕捉。
回頭看,這次真正補上的東西
這次做完以後,OpenClaw 不只是多了一組 log,而是多了一份可以回放的 AI 執行紀錄。
我比較在意的不是 Foundry portal 多了一個漂亮畫面,而是這幾件事終於查得到:
- 每次對話可以用
gen_ai.conversation.id找回同一條 timeline。 - 每次模型呼叫都有
chat.completions語意,而不是模糊的內部 provider id。 - Tool call 不再藏在文字 log 裡,而是在 trace tree 中成為可展開的節點。
- 多模態內容進 trace 之前會被 redacted。
- 成功與否不只靠肉眼截圖,而是有
oc eval foundry-trace可以重跑。
家庭 AI 助手的錯誤常常很微妙:一句稱呼、一張圖片、一段上下文、一個工具結果,都可能讓 agent 做出不同決策。有了 tracing,至少不用只靠印象猜。可以把那次決策攤開來看,再決定要改 prompt、修 plugin,還是補一條 evaluation case。